From November 2021 through March 2022 a total of 42 unique cohorts completed the IHCC Members’ Cohorts Survey. A large proportion of respondents indicated that they already have deep and diverse data-types, with demographic data most widely available and with a large proportion having the ability to recontact participants and with biospecimens available. Responders represented >21 million unique research participants with data/samples already available. Cumulatively, biosamples are available for >14 million participants and genomic data available for >8 million unique individuals. A wide range of environmental data has been collected by cohorts, including socioeconomic status (74%) education (83%), diet (76%), lifestyle (71%), and medication (71%).
A total of 25 cohorts self-identified as low and middle income countries (LMIC) and/or low resource setting (LRS). Additional responses from these cohorts identified funding as a primary challenge (63%), while 36% identified access to infrastructure and training as a challenge.
A large proportion of cohorts remains interested in Training opportunities, with IHCC webinars most favored among training opportunities.
Results
Preliminary Data to Support the Generation of an IHCC Global Resource: The IHCC’s Scientific Strategy & Cohorts Enhancement Workgroup has focused on identifying cross-cutting themes that impact multiple cohorts in order to better position IHCC to develop its strategy to serve the cohorts community more effectively. To this end, the IHCC recently developed a Cohort members’ survey to assess availability and cohort interests to create thematic workstreams for its future directions. Ultimately, the survey allows us to differentiate between what can be done with the data that exists today versus what requires new data types. The former is a near term opportunity, while the latter requires strategic and sustainability planning for longer-term outcomes. From November 2021 through March 2022 a total of 42 unique cohorts competed the survey, including 37 non-profit and 4 for-profit IHCC members (and 1 “other”). Respondents reflected the diversity of the IHCC as a whole, and were geographically dispersed across Africa (N=5), Asia (N=12), Australasia (N=2), Central America (N=2), Europe (N=11) and North America (N=10). Of these, 25 cohorts self-identified as LMIC/LRS. In total, these cohorts represented >21,000,000 unique research participants with available data/samples (and does not include an additional >7 million participants with data only (and no biospecimens available). The approximate breakdown of cohorts’ participant populations is shown in Table 1.
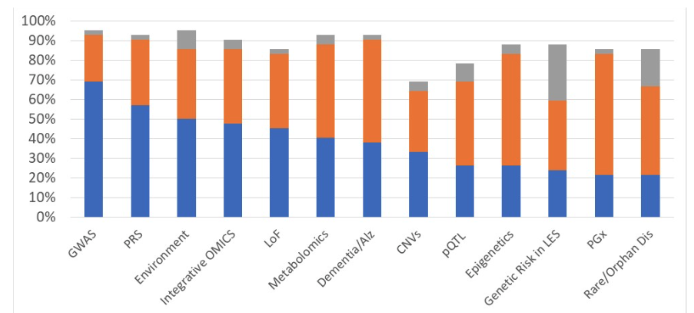
Research Interests: To guide immediate, medium, and long-term scientific objectives, survey respondents were asked to rate interest in, and availability of data toward, a range of scientific potential projects that members had previously identified as high-priority (panel reviews at 2019-2021 Annual Summit Conferences). The pattern of responses is relatively equal for LMIC and non-LMIC members (Figure 1). Total shown are the percentage of responders that are aligned to each respective category. Of note the majority of cohorts are interested in several cross cutting areas (meaning disease agnostic) including the ability to conduct and validate genome wide association studies (GWAS), polygenic risk scores (PRS), and capturing and using environmental data.
Figure 1: Survey Respondents rated scientific projects for Interest and Availability of Data. Projects are ranked from left-to-right based on availability of data, with GWAS most immediately actionable. Note, this is a curated list based on previous rankings, so interest is high for the range of projects.
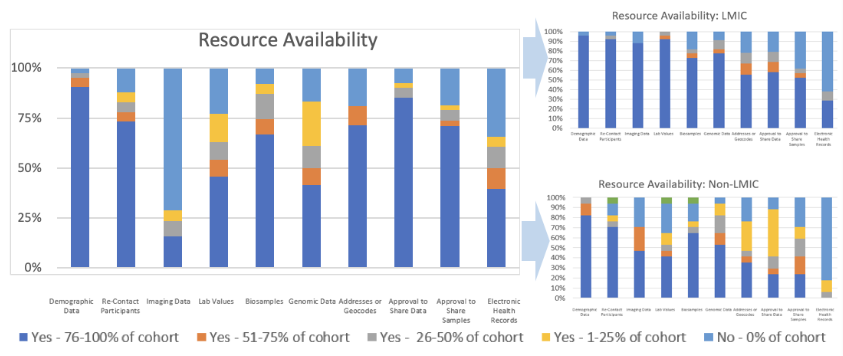
Resource Availability: A large proportion of respondents indicated that they already have deep and diverse data-types, with demographic data most widely available and with a large proportion having the ability to recontact participants and with biospecimens available (see Figure 2). Even though genomic data is available on only ~40% of participants, this represents >8M genomic data sets. These data underline the capacity and readiness of all cohorts, including LMIC/LRS-based cohorts, to collaborate in large-scale programs addressing a wide-range of potential studies. Cumulatively, data is available for >20 million participants.
Figure 2: Resource availability across the IHCC and between self-identified LMIC- vs non-LMIC-representing cohorts.
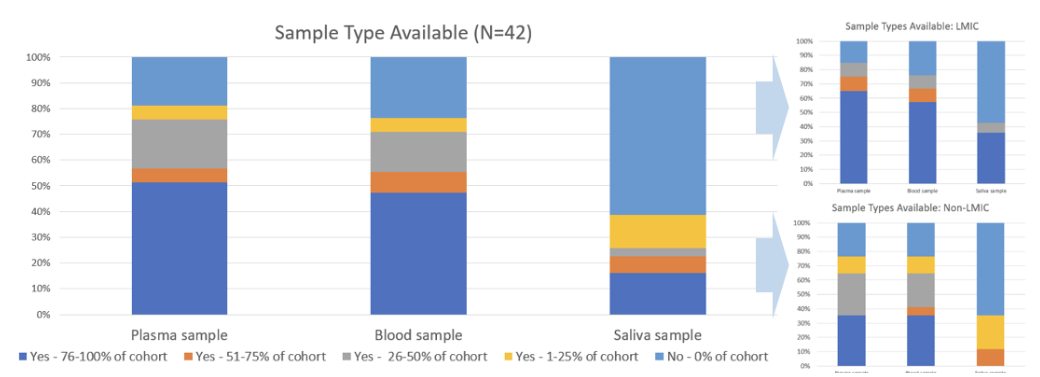
Sample Availability: Biospecimens with linked phenotypic data are among the most valuable assets of the cohorts for future research. As indicated in Figure 3, LMIC/LRS-based cohorts are comparatively well-placed to collaborate immediately on projects requiring biosamples and the IHCC as a collective is in a healthy position to launch large-scale projects. Cumulatively, biosamples are available for >14 million participants.
Figure 3: Sample availability across the IHCC and between self-identified LMIC- vs non-LMIC-representing cohorts.
LMIC Specific Considerations: While the survey data highlights a depth in resources for LMIC/LRS-based cohorts, this subgroup of cohort leaders were contacted for qualitative feedback on the challenges specific to the lower-resourced organizations. Of the 25 cohorts that responded, 19 provided additional feedback on this metric: for 12 of the responders (63%), funding was identified as a primary challenge, while 7 (36%) identified infrastructure and training. Four (21%) face challenges gaining access to populations and two (11%) identified a lack of opportunities to collaborate. As reflected in this proposal, the SSCE is actively working with IHCC Leadership to overcome these challenges and to adopt mechanisms to address them through investment, training, and outreach.
Training: IHCC members as a whole are enthusiastic about pursuing training opportunities across a variety of modalities, as shown in Figure 4. The Training workgroup is leveraging these data to follow-up with sites most interested in cohort exchange programs and mentorship opportunities.
Figure 4: Interest in IHCC Training activities among member cohorts. The Training Working Group will work to recontact sites interested in mentorship and exchange programs
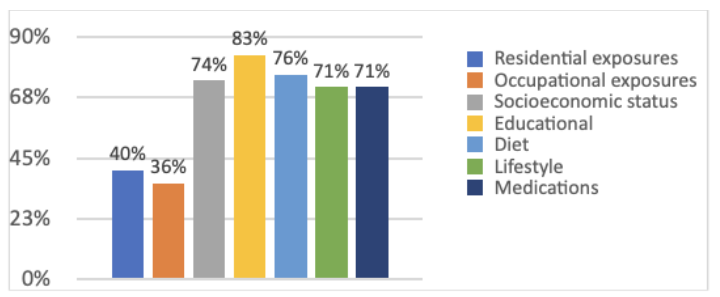
Environmental Data: More than 70% of cohorts have access to the residential address of their participants,providing an opportunity to study the health impact of any number of environmental factors through the generation of geocode data. Further, a wide range of environmental data has been collected by cohorts and is similarly primed for a wide of range of prospective programs, including socioeconomic status (74%) education (83%), diet (76%), lifestyle (71%), and medication (71%), while 40% and 36% have collected data on residential and occupational exposure (Figure 5). Linking environmental data to other cohort information and data will require the development of a policy for privacy preservation.
Figure 5: The majority of survey respondents reports extensive data on a wide range of environmental factors.
In summary, the diversity, depth and breadth of these data reflect the vast potential of the IHCC as a research platform and resource for the global community of longitudinal population studies. These data highlight the massive quantity of data already available across the consortium, largely untapped, with an active effort underway to address gaps where they exist.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.